Iceberg Sucks - But You Knew That Already
Published on January 01, 2026
Author: Jordan Epstein
Motivation behind the DataHarness
In my last year of work as a data developer at a high-frequency trading company, I’ve begun fighting a battle that may sound familiar to many - trying to get Apache Iceberg tables to support frequent low latency updates. While the title of this article makes it seem like I’m about to spend the next few pages shitting on Iceberg, I actually think it’s a great technology. It offers many improvements over Hive tables, and using an open format is critical for avoiding vendor/query engine lock-in, something which my company currently struggles with.
That being said, for our data cases that require frequent/streaming writes from many processes, Iceberg has proven to be more of a pain in the ass than an angry ex-wife. To commit data to an iceberg table, you need to:
- Write data/delete files to object store
- Write manifest files to object store
- Write manifest list files to object store
- Write a snapshot file to object store (completely copying most of the old one)
- Update the catalog to point to the new snapshot
This doesn’t lend itself well to fast data appends. Additionally, if you have multiple concurrent writes, all but one will fail and need to be retried. Einstein is misattributed with a quote that says trying the same thing over and over again and expecting a different outcome is the mark of insanity. But in the Iceberg world, it’s actually the norm.
Here are some reasons why that’s stupid:
- If all writers are doing append-only writes, we’ll still fail to commit
- If all writers are writing to different partitions, we’ll still fail to commit
- Optimistic locking means that writers will retry rather than waiting in a queue until other writers are done
- All of these small files are getting added to object store, meaning your company is going to burn all of your precious VC money on your S3 bill and your queries will be slow (5 cents per thousand operations?? I’d rather waste my money on OnlyFans!)
To mitigate the number of writes to iceberg (or other lakehouse formats), and by proxy the write amplification factor, the common pattern in the data space is to buffer writes in a message broker or transactional database (and then use debezium plus a message broker to sink the data to iceberg). Great, so now you’ve solved one problem, but have created another - how do I achieve exactly-once semantics?
This is where stream processing frameworks come in. Developers often use Flink or Kafka-Connect, both of which have a relatively steep learning curve (compared to writing your own application in the language of your choice) that feels somewhat unnecessary when writing simple data pipelines with no data transformations. Is that really all so necessary when you really just want to keep track of the last processed kafka offsets for a current iceberg snapshot?
Finally, Iceberg makes updating and deleting data a real challenge. In Iceberg, you currently have two options:
- Positional based (either via tuple or vector) row invalidations that target one row of a file
- Conditions that invalidate any row in a partition that matches them
There are some issues here, too:
- Positional deletes are not write optimized and significantly slow down streaming writes
- Equality deletes slow read queries to a halt, and can only be mitigated with expensive data compactions
- “Partial” row updates are not yet possible
While I clearly have my gripes with Apache Iceberg, for the sake of being intellectually honest, I’d say: the reason that people have issues with Iceberg is that they’re trying to force it to solve problems it’s not meant to solve. Iceberg is not an OLTP database. It is not meant for quick updates to single rows at low latencies, and those trying to force it to be are in for a rude awakening.
In the past few years, I’ve seen the proliferation of many technologies devoted to the improvement of fast inserts for analytical data:
- Apache Hudi
- Apache Paimon
- Apache Fluss
- Mooncake
- PeerDB
- Buf/Aiven /Confluent/RedPanda kafka/iceberg topics
- DuckLake for cutting out object storage for metadata
And I’m sure I’m missing many others. Many of these have common traits, such as merging memory/local NVMe with object storage, trying to integrate message brokers into iceberg tables directly, or using some form of arrow buffer to unify recently written data with cold data. And most importantly, all of their developers are smarter than me.
At the end of the day though, the specific technology doesn’t matter. It should be clear to all of us that when we want to solve a data problem that involves both transactional and analytical data, we need to integrate both transactional and analytical data stores. Do we really need a different startup for unifying every combination of OLTP database and OLAP data warehouse? Or should we just make it easier to make them composable?
Instead of focusing on building another HTAP database, I’d rather focus on building a general “data system unifier” to allow developers to fuse data systems together for their specific use case. In the next 10 years, I’m 100% certain that every major data tool is going to get rewritten in rust about 15 different times (and probably also implemented with Postgres). Rather than follow that trend, I want data developers like myself to be able to pick and choose any combination of these sources to make up a “table”. In that case, what properties should our “unifier” satisfy?
- Transactional semantics when moving data between sources: We shouldn’t see duplicate data or zero data in our “ table” when performing change data capture (i.e. postgres data becomes cold, delete it and move it to iceberg) or reverse change data capture (i.e. delete data from Iceberg and send to postgres since it’s about to be updated many times)
- Atomic schema evolutions: Schema changes should reflect in all data sources at the same time
- State alignment for sources that are not visible in the table itself: Even if you’re using Flink/other technologies as your main stream consumer, having a system to externally expose Flink checkpoint state allows query engines to read from sink table versions that are consistent with the checkpoint - this also means having the ability to centralize flink state, kafka consumer offsets, and sink table version in the same place, avoiding two phase commits
- Integration with all popular query engines: Spark, Trino, Presto, ClickHouse, Starrocks, Flink, hopefully closed source ones too
- Support for a wide range of table data sources: Kafka brokers, OLTP databases, arrow flight servers, open lakehouse formats, and static avro/parquet/orc files - all of this content can be combined as one table
- Allowing raw files enables brave developers to build their own lakehouse formats on top of this “table unifier” by writing additional scan planning logic
- Projection/predicate pushdown: Use existing query engine logic for each data source to run efficient queries
- Fine grained locking across data sources: Allows many writers to make concurrent changes to disjoint data sources
- Partitioning: Specify logic for how data is split across sources to perform query-time source pruning
Instead of trying to build an HTAP system myself, I’ll let our database and data warehouse engineers do what they do best, and instead try to simplify the process for engineers like myself to wire them together. Let’s call this “open composition layer” the DataHarness. When BasementDweller2048 creates a message broker in assembly next year, I look forward to welcoming his software to the fleet of available DataHarness sources.
Utility of the DataHarness
Simple Example:
Scenario:
- You want to provide low latency analytical data of your logs
- Your servers publish logs to many partitions of a kafka topic
- Consumer servers read from kafka, convert the data to parquet, and commit to iceberg
- If you publish too often, query performance will be bad, so you flush every 10 minutes, which is too long
- You read the data from Spark and Trino
- You’d love to have them read from both kafka and the iceberg table, but you have two problems:
- You can’t evolve their schemas at the same time, which breaks the union view
- Depending on whether your query engine reads from kafka or iceberg first, you may see missing or duplicate rows
- This is because they can’t be read at a consistent snapshot in time
Benefits of the DataHarness:
- Your consumer servers can update the DataHarness every couple of seconds with the highest known kafka offset per partition
- When the consumer servers flush data, they’ll atomically tell the DataHarness:
- The new “snapshot ID” of the Iceberg table
- The new “low offset” of the Kafka topic partition that was flushed (we don’t want to re-read data that is now in iceberg)
- When spark/trino query your table, they’ll union data from both kafka and iceberg without any duplicates or drops
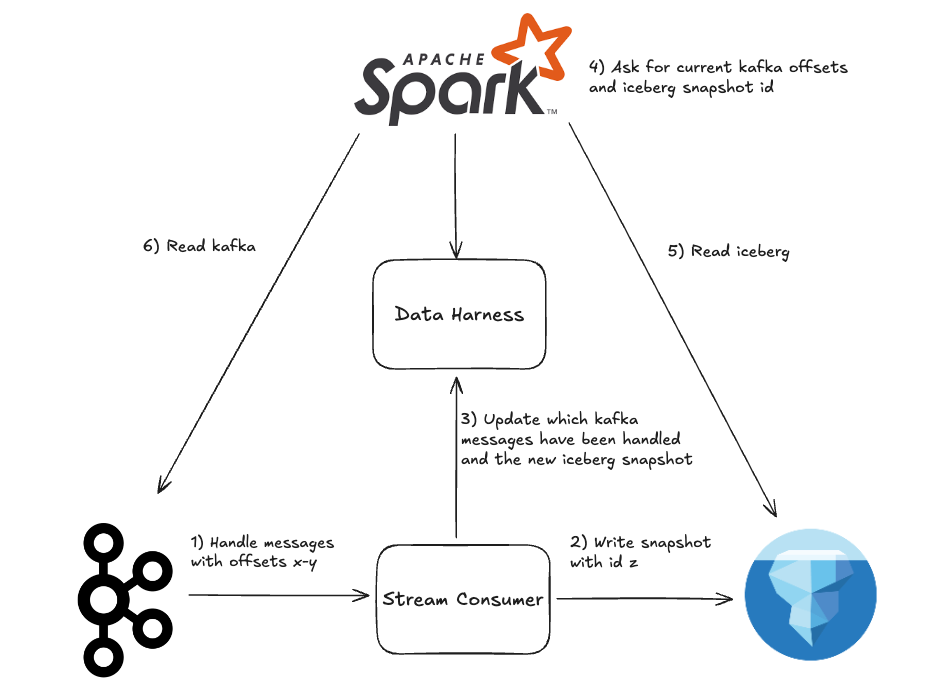
Medium Example:
Scenario:
- You have the same situation as the simple example, but now your logs may get replaced by other messages with the same log ID for up to 10 minutes
- Your kafka queue uses the ID as its message key, so any updates to a log live in the same kafka partition
- From kafka, you insert data into postgres, using a primary key to update rows where necessary
- After 10 minutes, you flush postgres data to iceberg to minimize the amount of row updates
- The server performing updates between postgres and iceberg uses equality deletes to invalidate the old version of the row in iceberg
- You only query the iceberg table, so data needs to be buffered for 10 minutes before ir is visible to clients
Benefits of the DataHarness:
- Data can be sourced from kafka, postgres, and iceberg with transactional semantics
- The server moving data from kafka to postgres updates kafka offsets/postgres read timestamps in the DataHarness
- The server moving data from postgres to iceberg updates postgres/iceberg read timestamps in the DataHarness
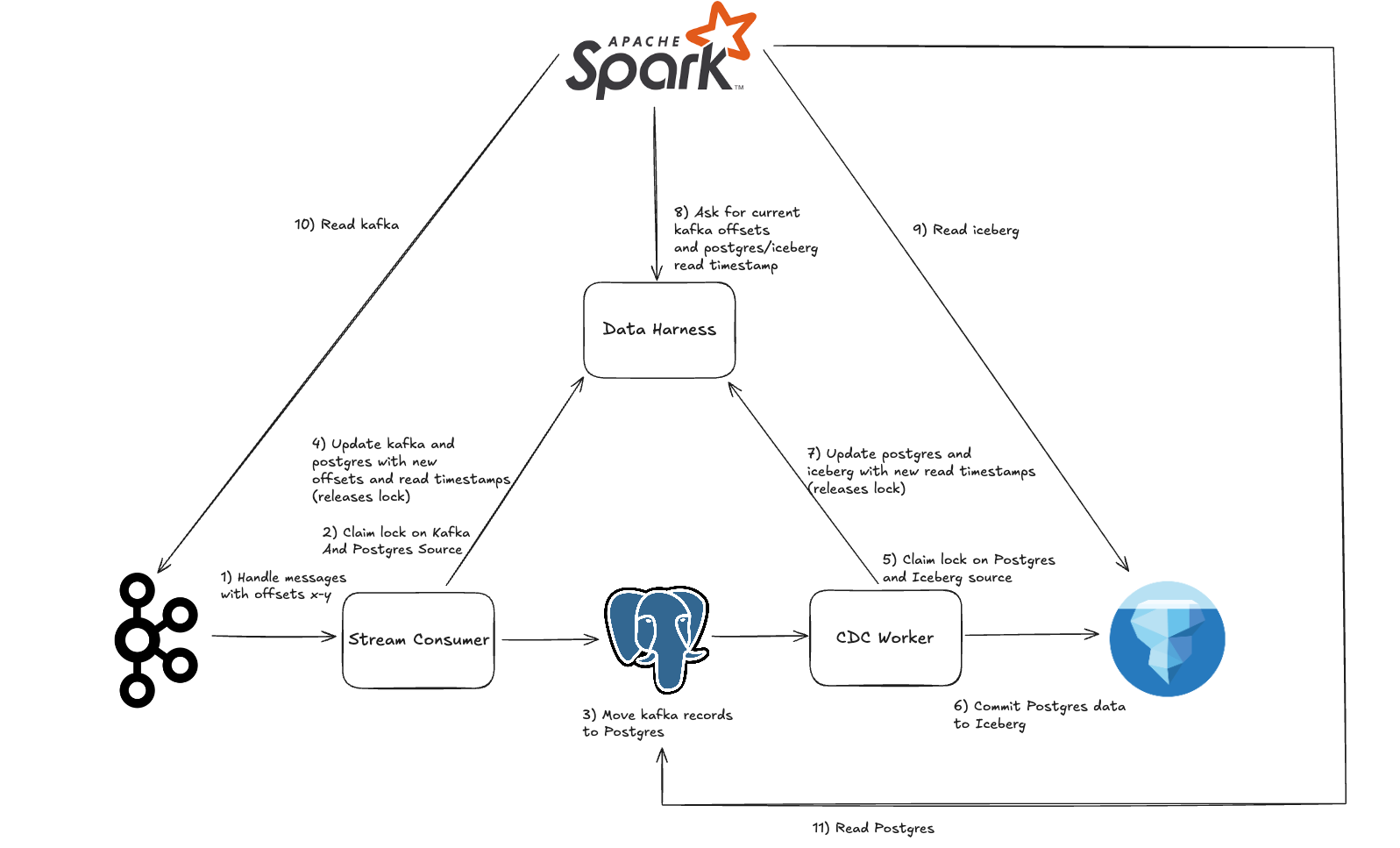
Note that they both modify the current “read timestamp” of the Postgres table! This could lead to some nasty race conditions! Instead, before exchanging any data between data sources, they:
- Grab a lock in the DataHarness on the Postgres source
- Move rows from kafka to postgres, or Postgres to Iceberg
- Update the state of each data source
- Release the lock
Finally:
- Spark/Trino read the DataHarness to get the appropriate source offsets/read timestamps, and then query them
- Using simple SQL, we can take our union view and create an auxiliary “primary key view” which deduplicates rows
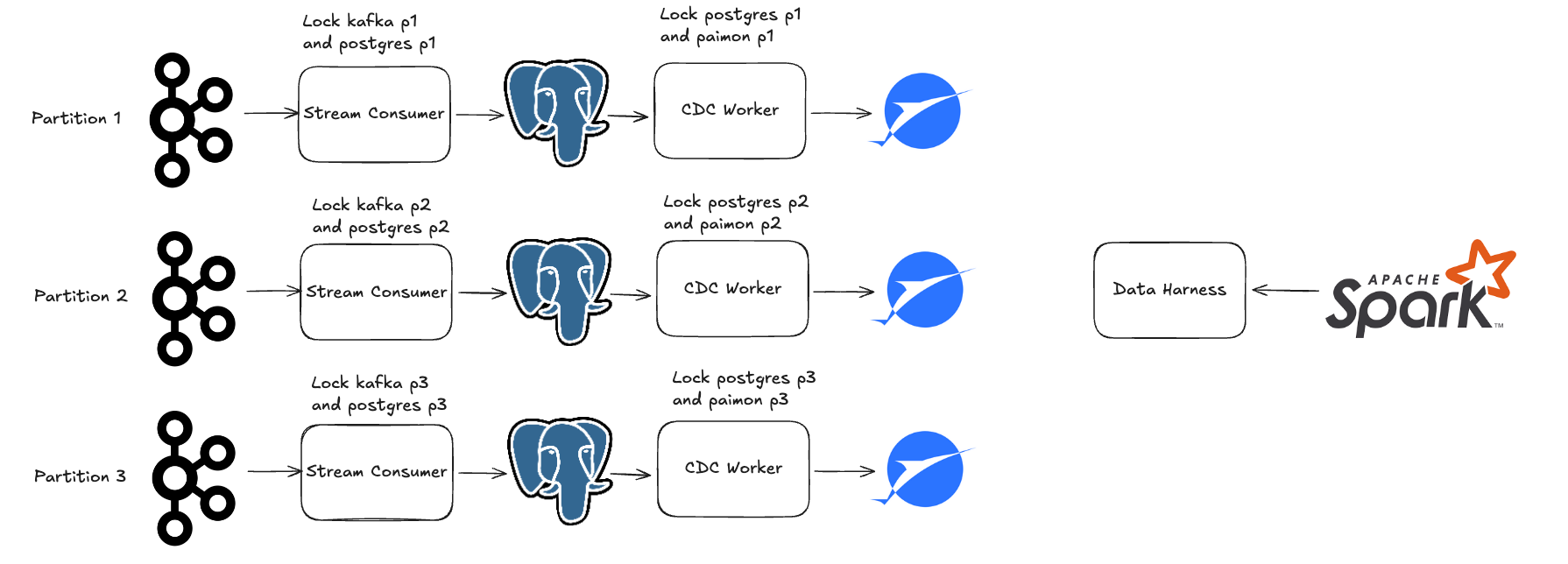
Expert Example:
Scenario:
- Same as before, except you need more than a single Postgres instance to support your incoming kafka load
- Multiple kafka topic partitions
- Shard out your Postgres table using Citus
- Commit to many LakeHouse partitions at once using Apache Paimon
- Ensure that each kafka partition’s data goes to one postgres partition which goes to one paimon partition
- Query the data with Spark (Paimon doesn’t work with Trino)
Benefits of the DataHarness:
- Use a different “source” for each partition of the kafka topic, postgres table, and paimon table
- Complete concurrency without any synchronization across partitions, DataHarness locks can be grabbed for one partition at a time
- Kafka offsets, postgres read timestamps, and paimon read timestamps are all modified one partition at a time
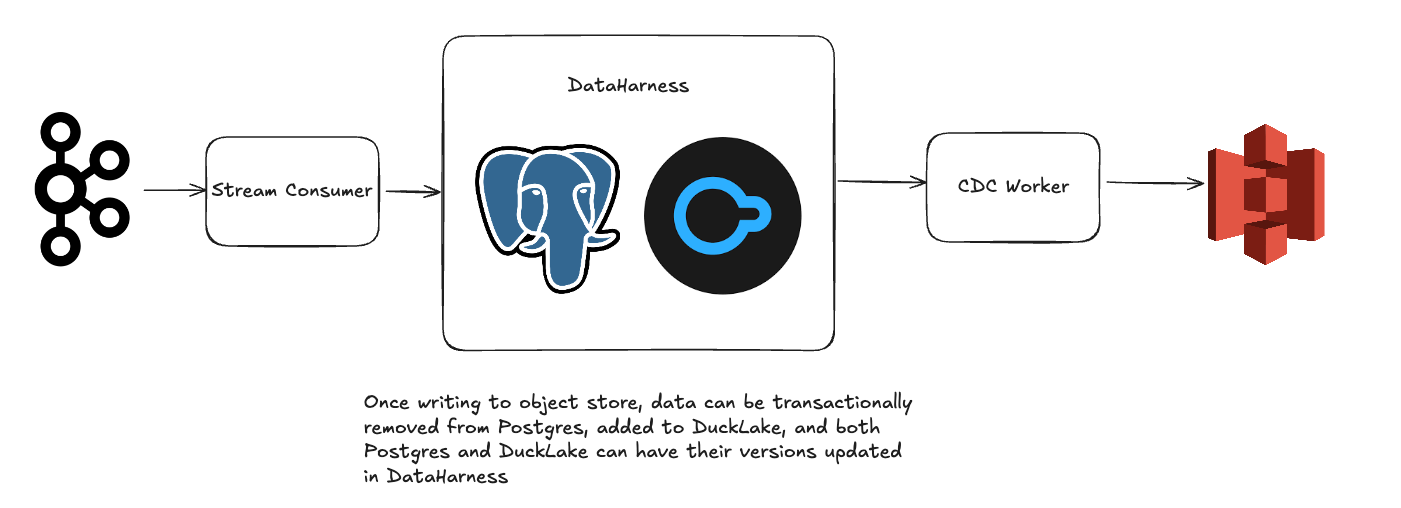
Basement Dweller Example:
- Same as the medium example
- Instead of using Iceberg, you use DuckLake
Benefits of the DataHarness:
- You can co-locate your OLTP data, DuckLake metastore, and DataHarness in the same Postgres instance
- Performing committing a CDC operation between Postgres and DuckLake just takes a single database transaction
Conclusion
As you can see, there are benefits to composability!
Well, this turned into more of a manifesto than expected. Seems like we’ve got a lot of ground to cover.